Download Applying Concept of Inferential Statistics (Estimation of Parameters) Worksheets
Click the button below to get instant access to these premium worksheets for use in the classroom or at a home.

This worksheet can be edited by Premium members using the free Google Slides online software. Click the Edit button above to get started.
Download free sample
Not ready to purchase a subscription yet? Click here to download a FREE sample of this worksheet pack.
Definition:
Inferential Statistics uses a random sample of data from a given population or from a larger amount of sample. It is also known as Null Hypothesis Testing.
Summary:
The goal of inferential statistics is to make a conclusion from the sample and apply the conclusion to the population where the sample is drawn. When you estimate the sample from the population, the sample data is most likely to have a near or almost equal value to the data of the population.
POPULATION AND SAMPLE
What is a POPULATION?
Population refers to a large group of people, objects animals, or events that can’t be sampled one by one. Examples of population are:
- Students in a university
- Fishes in the fishpond
- People living in the Philippines
What is a SAMPLE?
Sample is the random selection from a given population. They are used to draw conclusions for the whole population where they were obtained. They act as the “representative” from the given population. Examples of sample are:
- 5 students to do a survey for the university
- 10 persons to do a survey for the whole population
- A survey for 15 customers to see if the customer service of the company is doing good as a whole
Example of Population and Sample Relationship
- A traveller would like to know what countries do people like to travel the most. He did a survey to 10 people from different countries to obtain the data that he needed.
- A talent agency needs to know if people living in the USA prefer singing, dancing, or acting. He made 5 person from the different parts of the country to do a survey.
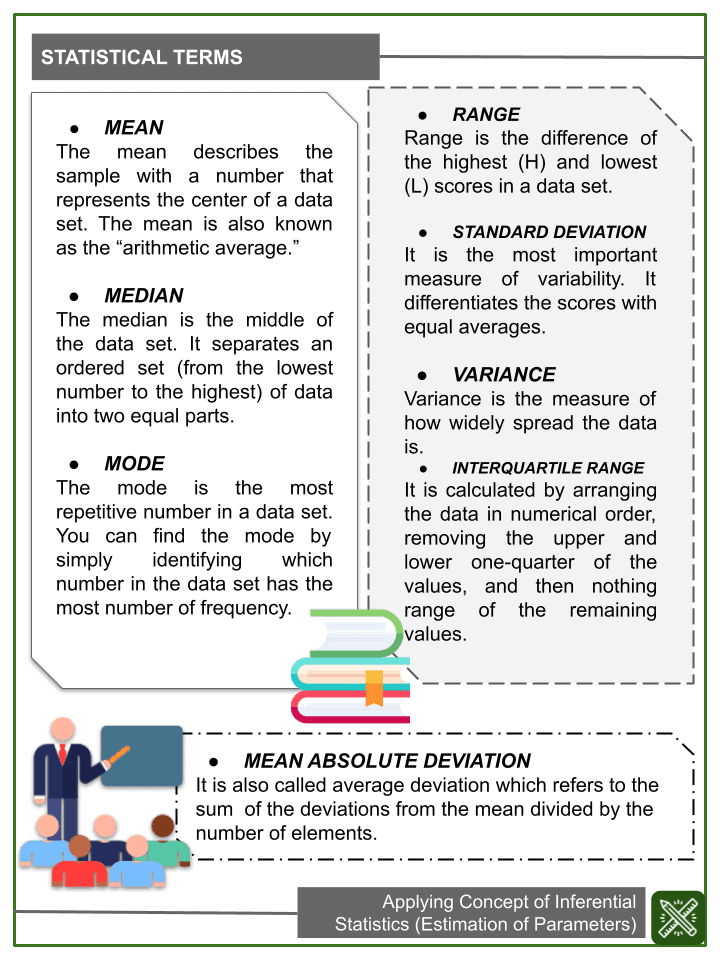
STATISTICAL TERMS
- MEAN – The mean describes the sample with a number that represents the center of a data set. The mean is also known as the “arithmetic average.”
- MEDIAN – The median is the middle of the data set. It separates an ordered set (from the lowest number to the highest) of data into two equal parts.
- MODE – The mode is the most repetitive number in a data set. You can find the mode by simply identifying which number in the data set has the most number of frequency.
- RANGE – Range is the difference of the highest (H) and lowest (L) scores in a data set.
- STANDARD DEVIATION – It is the most important measure of variability. It differentiates the scores with equal averages.
- VARIANCE – Variance is the measure of how widely spread the data is.
- INTERQUARTILE RANGE – It is calculated by arranging the data in numerical order, removing the upper and lower one-quarter of the values, and then nothing range of the remaining values.
- MEAN ABSOLUTE DEVIATION – It is also called average deviation which refers to the sum of the deviations from the mean divided by the number of elements.
Applying Concept of Inferential Statistics (Estimation of Parameters) Worksheets
This is a fantastic bundle which includes everything you need to know about Applying Concept of Inferential Statistics (Estimation of Parameters) across 15+ in-depth pages. These are ready-to-use Common core aligned Grade 7 Math worksheets.
Each ready to use worksheet collection includes 10 activities and an answer guide. Not teaching common core standards? Don’t worry! All our worksheets are completely editable so can be tailored for your curriculum and target audience.
Resource Examples
Click any of the example images below to view a larger version.